
It’s hard to guess the future of Machine Learning (ML) for the extended future, but we can make short-term predictions based on available evidence. We will consider going into depth and deliver information that developers can relate to. Those passionate about building ML products can get standout ideas on what to focus on so that they gain a competitive edge in the tech market.
Here is what you will learn from this article.
- What is feature store?
- How is ML being used in retail today?
- Machine Learning in retail: some statistics
- Top ML investment predictions for 2022
Let’s get started.
What Is Feature Store?
In simple language, a feature store is a single pane of glass for sharing all available features. So far, successful outcomes were registered with those tech companies that could build their own feature stores, including Uber, Twitter, Google, Netflix, Facebook, Airbnb, etc.
Have a look at this picture. What do you see?
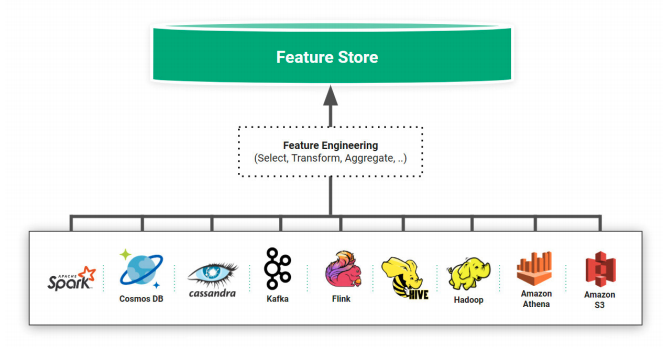
This is exactly how the feature store looks like. But is the average human mind able to develop features stores as Uber or Facebook did? Very rarely. Due to the complexity of bringing these projects into production, ML practitioners need to standardize and automate the feature store production process through feature engineering.
Let’s have a look at how ML is being used in retail today. You will get a hands-on understanding based on a specific example.
How Is ML Being Used in Retail Today?
The retail sector is one of the most positively affected sectors by ML technology. How so? Let’s come up with a couple of benefits ML has offered in the retail sector:
- Personalized sales
- Dynamic adjustment of prices
- Better inventory management
- Adjustments based on past customer behavior
- Better predictions based on past customer behavior
- Website optimization and in-app and on-web customer interactions
- Better segmentation of customers based on past experience.
Now let’s get back to the feature stores mentioned earlier. How do you improve sales based on past customer behavior? To do that, you need to know some technicalities of the feature stores.
Below are some operations to perform:
- Numerical imputations
- Random sample imputation
- Categorical imputation
- End of distribution imputation.
Concerning the example above, you may need to run One-Hot Encoding. One-hot encoding is one of the most used methods in machine learning. The method assigns 0 or 1 codes to the imputed values. The values express the relationship between grouped and encoded columns. This method allows you to group your categorical data without losing any information. Here is how it looks.
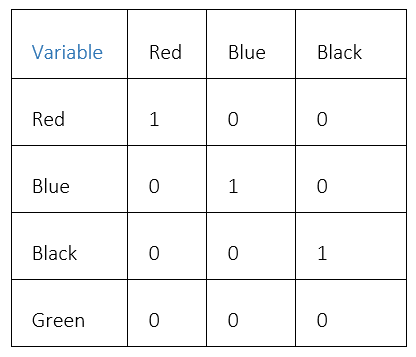
You can do the same using Grouping Operations with the help of a pivot table or sum and mean functions. Have a look here.


Finally, you may want to apply multiple prediction pipelines to monitor prediction patterns. Here is how it looks.
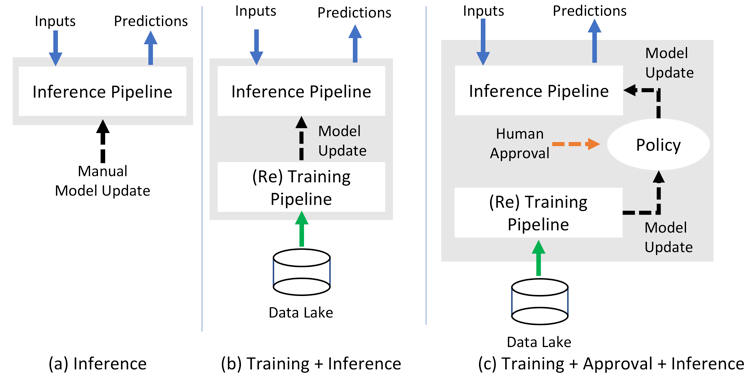
Machine Learning in Retail: Some Statistics
Let’s have a look at the figures.
“73% of customers are fed up with being presented with irrelevant content.”
~Source: Study by Janrain
What do customers prefer instead?
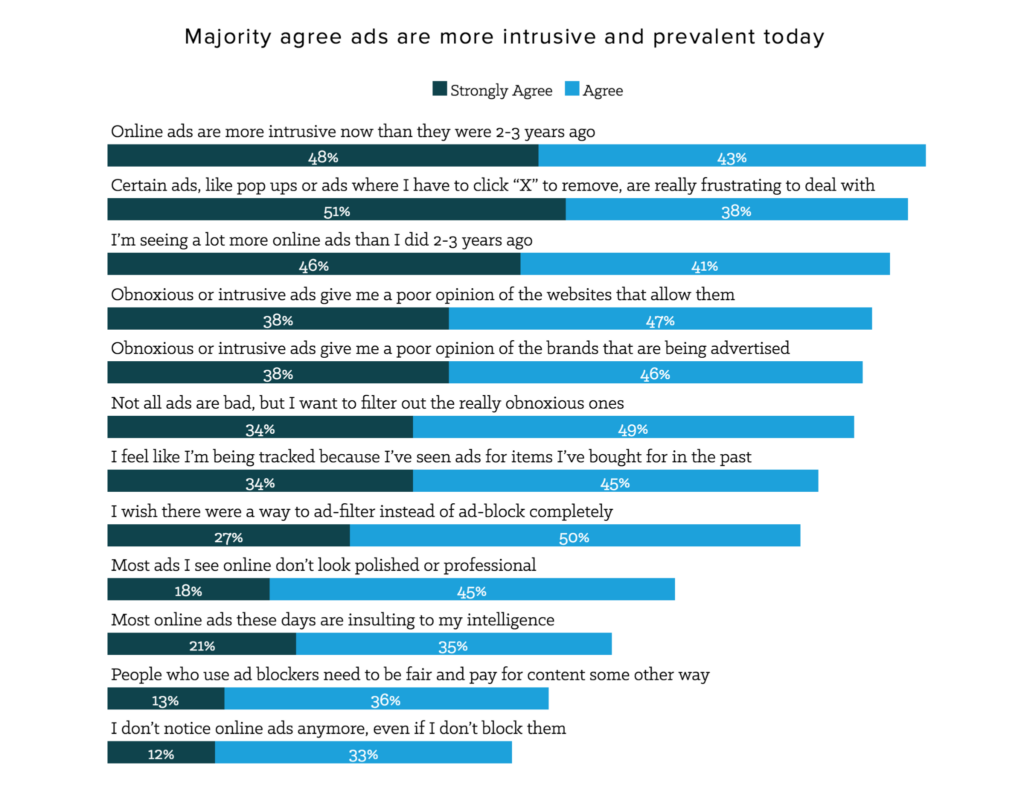
Statistics show that they are fed up with ads and want more personalized services, and here the chatbots are of immediate help. Have a look at the graph, and you will realize that the time of ads is coming to an end.
“45 percent of respondents are deploying machine learning for customer engagement in their organizations.”
The data is taken from Statista concerning machine learning use cases in the retail industry worldwide as of 2019.
On the other hand, Louis Columbus, a former Forbes contributor, projects a Compound Annual Growth Rate (CAGR) of 42.8% from 2018 to 2024.
“Projected to grow at a Compound Annual Growth Rate (CAGR) of 42.8% from 2018 to 2024, the global Machine Learning (ML) market will be worth $30.6B in four years.”
~Source: Forbes
Top ML Investment Predictions for 2022
In 2022, big data management will astoundingly grow to include factors like health care, the automotive industry, and retail. More companies will focus on apps enabling us to understand and use data more effectively, with faster and more accurate outcomes.
Forecasts suggest that China will be on top of ML investment.

Given the popularity of ML in 2022, you may think of investing in the sector. Whether you are a developer or a business-minded person, you may need some guidelines on where to invest.
According to our observations and the evidence provided by research institutions, here are the two sectors predicted as the best ventures in 2022.
- Big data and virtual reality app development
- Development of apps to ensure security.
Application development will be a significant force to drive the expansion of new appliances and things. Just in one or two years, developers will come up with software applications that you may think are outside the box today. Sectors like Artificial Intelligence, the Internet of Things, Augmented Reality, Virtual Reality, and so on will be on top of the play. The tech market will see a boom in tech engineers and data scientists concerned with new and innovative ways of building a machine learning app.
All well and done. But what about the security measures? Virtual reality apps require certain interference into the public space. Given this fact, robust security measures will be developed to protect the tech environment from cyber-attacks. A good example is Domain-based Message Authentication, Reporting & Conformance (DMARC) that protects privacy, enabling blocking unwanted emails or sending them to the junk folder.
Conclusion
So, what’s the deal? The deal is that we live in a world of big data and massive information that needs to be systematically categorized. No human brain can deal with such huge data. Therefore, machine learning is going to expand rapidly and efficiently soon, sooner than you think. At a very high level, machine learning will think instead of you making accurate predictions when fed with data.
The question is, how much manual involvement is needed? Who will create data feed specifications? For what purpose? Are they secure? How much should personal space be sacrificed to get faster and more reliable data management systems?
These questions need to be addressed if we ever want to trust big data to machines rather than to humans.
I am a technology writer and Product manager at Addevice, a mobile app development company. I’m a content enthusiast who keeps a tab on most sites that take this niche to the next level.



















